Understanding Aggregate Functions Performance
Understanding Aggregate Functions Performance
What are Aggregate functions?
Functions like AVG(A), COUNT(*), MAX (A), and MIN(A) used in DB are useful but if used in the wrong way they can show visible performance aggregation
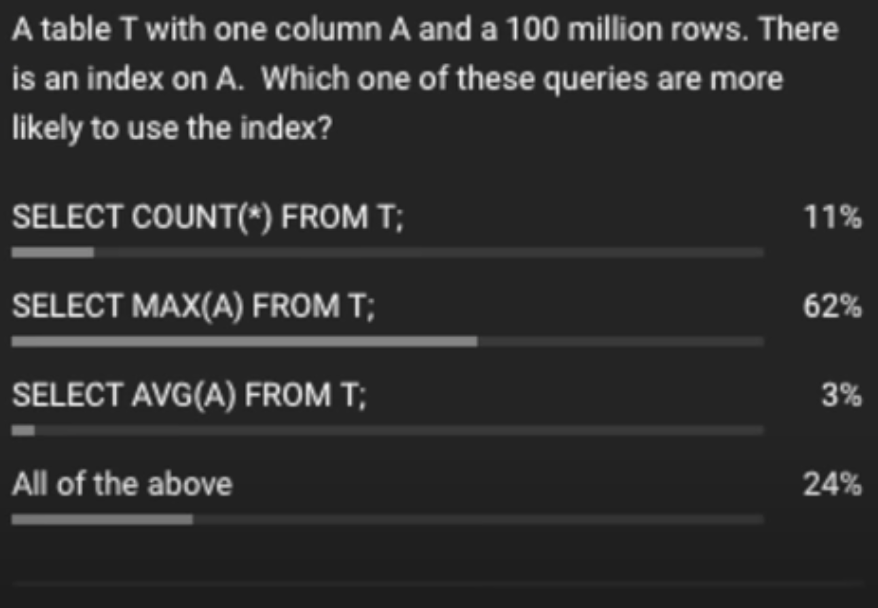
If asked which of the following is more likely to use the index, the answer will be MAX(A), but why and not count ()? , as by initial thinking the COUNT() seems more likely to be using the index to calculate the total count of the rows
Analysis: COUNT(*)
1
Select count(*) from T;
- To count every single entry in the table have to scan the entire table
- Scanning the table would have been easier if it was stored sequentially
- Scanning the B-tree sequentially is not easy
- It is easier to read B-tree page by page
The first thought which comes to our head is that why shouldn’t the index keep a count of the values in the table, why are we not doing that? If we started doing that we will just kill concurrency
- Counting is one of the hardest problems in the database systems
We assume that there is a single reader-writer in the system when we are using it but in actuality, there are multiple read writers in a database and currency and there are multiple read and write happening in the database completely unaware of each other, inserting new records at the end
Now if we introduce a counter in an index of a DB or a data structure through some sort of mutex or a lock, and whenever a new CRUD operation comes in have to update the count
- If we Start keeping the count we lose the throughput
Databases are still fast even if we use count just this Aggregate function does not use the index for its work, although there is some exception if we are using the where clause and that uses a field that is indexed and has a small collective number, that will use the index in that case but if we have an unbounded count query it will not use that
This like these should be thought of and there is no one answer and need to be analyzed all the time
Analysis: AVG(A)
1
select AVG(*) from T;
AVG function is something we need the whole count of same as the COUNT(*) but also iterate through each of those entries to calculate the thing, the moment we start iterating through each value we are going to the DB to fetch the value and less likely to use the Index
Exception. : Clustered vs Non Clustered Index
Analysis: MAX(A)
1
Select MAX(A) from T;
MAX is the best we can use for the index if we look at an index in which are B Tree are structured and organized into pages and B+tree is designed to be sequential in order, so if we ask the index we already know the first page of the index and the last page of the index
This means the first page will have the lowest value or number of entries (smallest entry) and the last page will have the max entry, we can use Big O(1) to get to the first page or the last page at the same time cost, and since we can traverse to the last page of that key we can get the maximum of that page
- The database might need to check if the entry Is alive in the case of Postgres, by fetching that page to check if the value still exists or somebody didn’t delete it or someone updated it, there is where Heap and other concepts come into the picture
In a nutshell, MAX() and MIN() are the best when it comes to utilizing the index, and if we don’t have the index the database will suffer iterating through all the entries to find the maximum and minimum value
- Any IO workload hates randomness be it a database or reading the value from drives, to SSD which is random read and writes
- Best to do IO operation in sorted and ordered things
- Therefore sorting is important, if things are sorted it makes the operation and so many things efficient and easier to work with
Best Case Scenario
- B Tree is best if need a page from the tree, but not for traversing sequentially though the entire DB
- We can also store the data by column, ie to find maximum marks in maths pick the column Maths and store all the values in that, so that when we need the max or avg value in maths just a single read on the page will give that column with no garbage unlike the row-based storage model
- If we look at column-based storage values, they are best for aggregation as a single read will give a collection of values and nothing else giving a lot of IO (ie instead of getting all the non-required details like the student details name, etc instead of required just the marks in subject maths)
- This is approach is best utilized in OLAP
Clustered Index
- The clustered table is a table that has a primary key
- The table is ordered around that primary key
- If we have a value that is an integer so if we are inserting the value 1 it is the page 1 and all the values are inserted into order and the new incoming values are also ordered
- Oracle calls it an Index Organized Table (the table that is organized around the index)
- SQL Server calls it (Clustered Index )
In this setting, the read is faster due to the sorted and ordering nature but the inserts are mostly costly as before the insert the location must be found out inserting into it, which is not the case in the case non clustered index in which all subsequent inserts are appended into the end
Clustering Sequential Write
- If we are doing the sequential writes the last page will be the busiest page
- As the hundreds of inserts are coming in the last page value or position to insert in will always be fighting off for the mutex to lock it before inserting the value
- There might such cases where random writes will be faster than the sequential ones (advanced concept to think about)
- No 2 CPUs can write on the same piece of data at the same time (MPI, CUDA multithreading domain comes into the picture, etc)
Primary Key as Random?
- Using UUID as an example, when we insert we don’t have these locks anymore so our writes will be fast as no 2 writes will have to complete on the same page and each will have their own memory location
- But for writing, we need to pull the page into the memory and write the value to write to the disk back as with all the random writes many pages will be pulled into the memory and soon memory will start filling up which is not the case when writing to the same page as only 1 page will be needed to be loaded into the memory for writing and the only significant cost will be CPU to get the mutex lock
- Both the approaches have CPU vs Memory costs linked to each other
- UUID approach will start fast but once the memory pool is filled it starts slowing down when this happens the checkpoint happens when the DB needs to write everything back to the disk consuming all the resources to flush the data back to the disk, this process is expensive and if this keeps happening again and again as we fill the memory over dirty pages and have to flush them
- If we just changed 1 bit and wrote the entire page back, there is a better approach to that
Summary
If we are using the aggregate function and the tables are clustered then it will utilize the index as the index is the table as it as a clustered index, with all the nodes in the B+ tree
Reference
- https://youtu.be/L-8_CjV6sH4
- Page 151 + in Notes (Gate Notes)