Cost of Hash Tables
Cost of Hash Tables
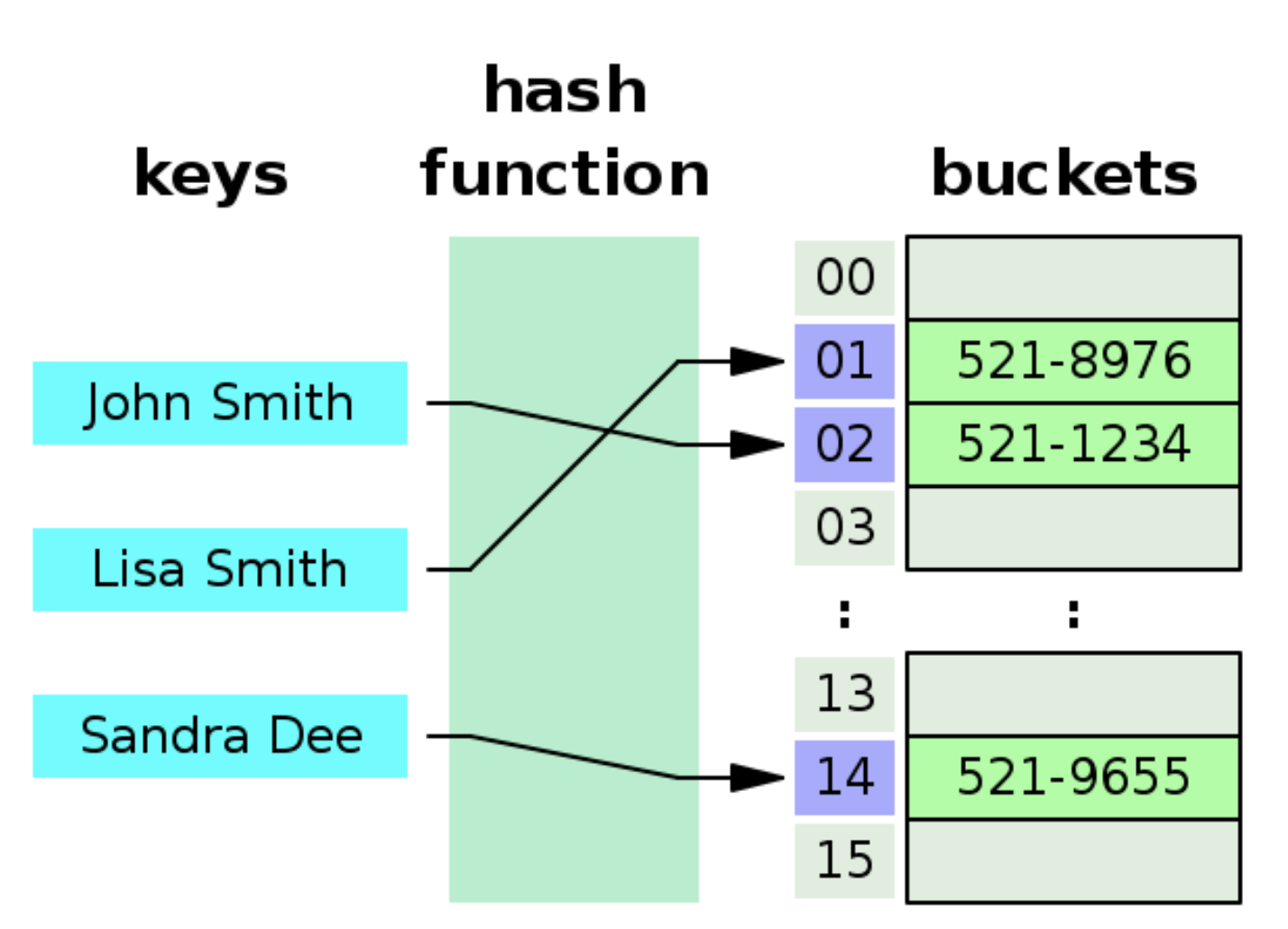
Hash Tables are effective in many places like
- Caching
- Database Joins
- Partitioning
- Distributed Databases
- Sets
- Load Balancing
Limitations and Costs
In software engineering, we get away with not knowing how something works until it breaks and we have to deep dive into its working
- To understand what hash tables need to start with an understanding of what arrays are
- The concept of Arrays is a consecutive block of memory
- Because of the continuous block of memory, no matter how long the index is we can go any node of the element in almost constant time, Big(O) due to being byte-addressable
- If we ask the CPU to fetch the value of an index, it fetches by using the memory address of the first index of that array and adding the required index X size of each element to get the memory address of that element,
- Hash Table can be thought of in the same family as the arrays (kind of glorified arrays)
CPU Fetching the Results
- CPU fetching the results from the memory, depends on factors like the distance between the CPU and where the memory is located which is easy to calculate in single CPU architecture, both in Multi CPU architecture like multiple CPU on the boards accessing the single memory
- Each CPU has to compete to get the access to the memory as a single CPU gets access to the memory at the time to perform an action
- In some architecture, there are different memory for each CPU allocated, and each CPU accesses its local memory, which is faster and more efficient
- But there might be cases the CPU needs to access the data in the memory that is local to the other CPU (Non-Uniform Memory access) which can be slow
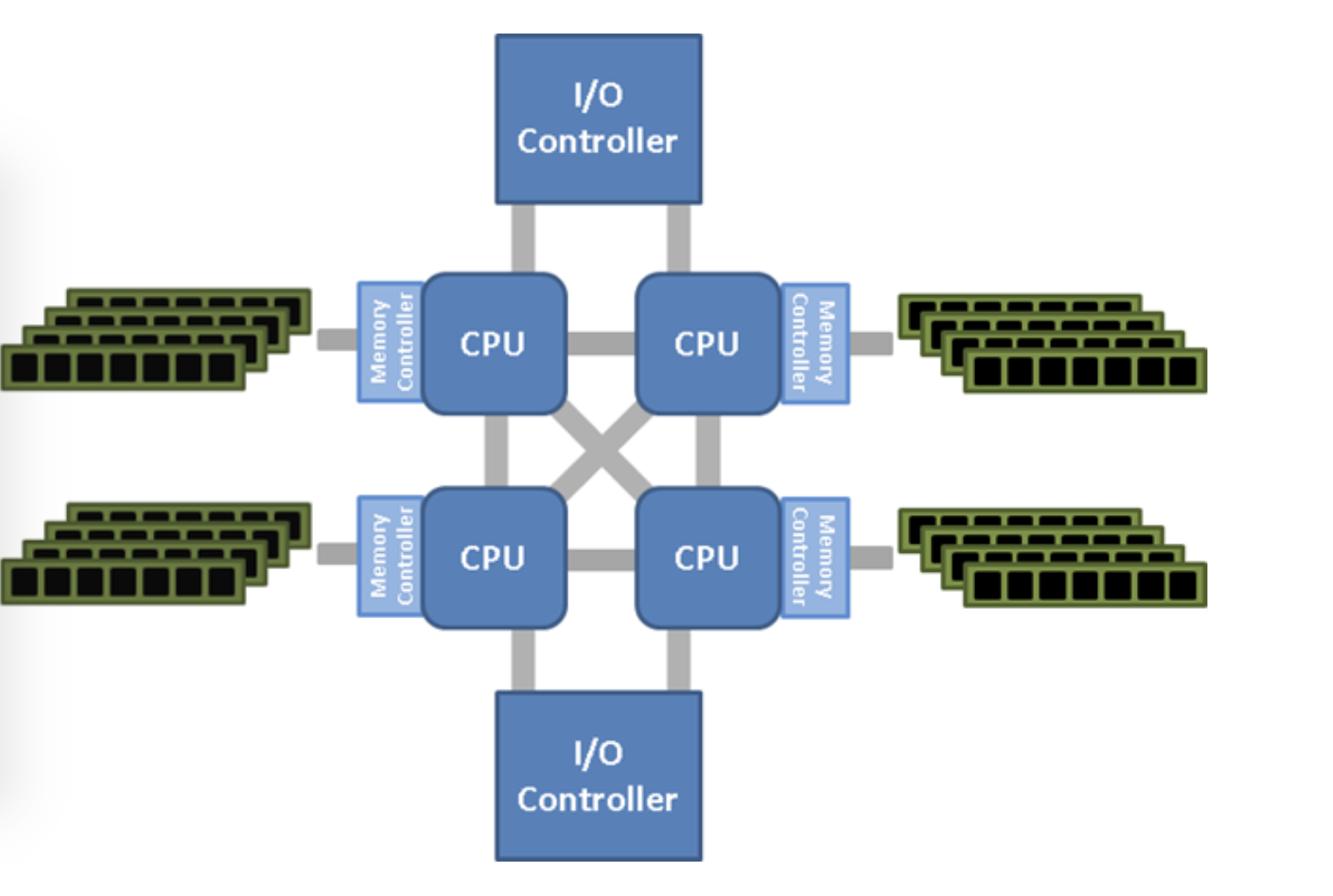
- To overcome this limitation by bringing the memory closer to the CPU apple has implemented a unified memory concept in the Apple Silicon by integrating the CPU and Memory together on a single chip with M1 max with both the CPU placed together that the cost of 1 CPU accessing the memory local to the other CPU is negligible
If Arrays are there why do we need Hash?
- The problem with the array is that it is integer based, so cannot be used in cases where the key which we want cannot be used as an index
- To solve these cases is where Hashing comes into the picture to utilize the array in an efficient way
- Ex : Consider a case when we want to store the mobile number of the user to the name of the user, the 10 digits mobile number is greater than what we can use as the index of an array since the index of the array are integers and the memory required can exceed to that of available physical memory or the index is the name and we want the address for it
- Sol: We Build the Hash Table, ie take a hash function and generate the Hash for each of the IDs (if we hash the same value again we get the same hash again )
- Now give that value, we calculate that index that points to that array, the easier method to do that is using the Module function
- When we get the hash value we modulo it to the size of the array or index and we can immediately go to that array value in that index and fetch that value
- Now given a key we can find the value in the hashtable using the power of the array
Collision in Hash
- There can be a situation where two students have the same name when generating their hashes the hash will be the same but since the students are different they will have different student IDs that we want to lookup
- How are collisions avoided in hashmap ? (Java 8 vs Java 11)
Uses of Hashes
- One Popular use case of hashes is in the database join, when we join two tables based on the foreign key we use the concept of the Hash table
- Supposer we want to join two tables the company table and employee table on of the relation to do that we internally create a hash table (which incurs a cost) so while creating join we pick the smaller table as creating a hash is expensive since we have to loop on every row, take the value and generate the index and store the index in a hash table
- While generating the hash table we already know the size of the table therefore we can already ask the RAM to allocate us the memory for the hashtable/index which we will be needing and then we start filling the hash table
- When we have built the hash table we have an array in memory with all those values but there is a mapping between the key to the index value where the data is stored
- Now we go the other relation, iterate through each of value, hashing each entry and generate the hash for the same and look up the index using the hash table and bring the values corresponding to it (probing continues)
- If we find the value during the probing and the value match we give the output, if it does not exist we do not join it and create an output relation as a result
- The above example was classical hash join and there are more optimized Joining hash techniques being used in DB because if the table is big cannot be fixed all in the memory
- Hash tables are useless if we cannot load them into the memory, as Hashtable is internally an array that needs to be fit into memory to use the byte addressability of the RAM
Limitations of Hash Tables
- Hash Tables have to be fit into the memory to be utilized and that is a big problem, like thinking of using the entire key. value or database into the hashtable 😂😂 , even to build that thing the entire thing would need to be scanned to create a hashtable out of it and load into the memory which is costly ie Cannot have Billion size hash table
- Building Hash Table has a cost therefore always use the smallest column to choose from for building joins, one can partition it into chunks and hash chunk at a time
- Deleting and Adding to the Hash table is hard and screws up everything, ex (if we are doing modulo of 10 to all the values, but if we add another element and make it to 11 then we will have to hash the entire thing to make it work with modulo 11) and will have to rehash the entire thing to work with it
- If we are using Hashing in Sharding of that database where we are using a hashtable to identify which server to point at for incoming request but if the number of server of increase or decrease the whole the whole hashtable has to be created again to work with the new change size (ie DB like Cassandra can handle these problems by re-sharding)
- Consistent hashing was developed to solve this problem
Reference
Source
This post is licensed under CC BY 4.0 by the author.