Machine Learning Samosa
Project S.A.M.O.S.A
Smart Autocomplete Machine Optimised Search Assistant 😋

So one fine evening of 23 September 2020 an Office Mail arrived announcing the Infineon iHack 2020 in which there were multiple tracks for each domain and had a specific problem statement for each track one had to build a solution for in a team.
Armed with my ML knowledge since the start of 2020 I quickly formed a team with my friends Shraddha, Dhanushri, Shreesha and since we had some idea about image processing and ML and statistical data but no clue on applied NLP ML, we started with what was most important ………deciding a cool name for project, it was rainy season in Delhi and in sept and mostly our project discussion were on weekends hence it magically landed on the word samosa, the full form of it came afterward
So here is how we approached the problem of building an autocomplete ML model from scratch and won as 2nd runner up in the first-ever Machine Learning Hackathon.
Step 1 - Understanding the Problem Statement
So our problem statement was to create an ML model trained on a given dataset that will generate the most accurate and relevant autocomplete give a uni-gram or bi-gram eg if the dataset includes an article on semiconductor then typing “Semiconductor” and the partial world “in” should give out [industry,intel, insulator, inductor] to achieve what we use in google autocomplete suggestion that came in 2010 around
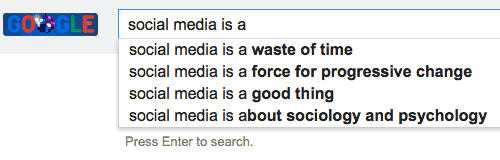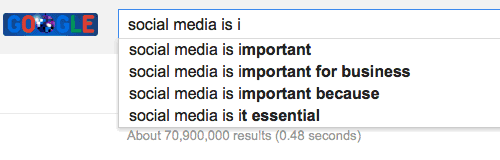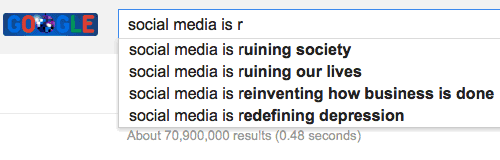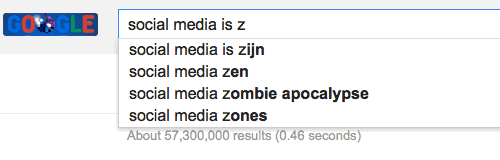
Step 2 - Knowledge Ramp-up
Since we had 2 months of time to prepare and no practical NLP model hands-on to get an idea of what we were getting into , we started looking up various approaches that can be used to solve the problem , we all had prior knowledge of Tf-IDF and Markov chain which were part of NLP course in University but lot of buzzwords GPT-3 and other advanced model made us doubt ourself that there might be a better solution to it that we don’t know and since the other objective apart from solving the statement was learning too so we all set out to learn from whatever resource we could from medium articles , Youtube , Coursera in which i ended up doing entire 4 course specialization for remaining 80% if time until event to know the complete start to end of Natural language processing from state of the Art models to simple sentiment analysis and word count techniques, Here is my certificate from Coursera for it which was the collection of following courses :
- Natural Language Processing with Classification and Vector Spaces
- Natural Language Processing with Probabilistic Models
- Natural Language Processing with Sequence Models
- Natural Language Processing with Attention Models
After taking a complete tour of the landscape of NLP for finding the best (kickass) solution to fit our problem we decided to use a Hybrid approach to use Tf-Idf and Word2vec for our solution. As a regular podcast listener, I also gained some really useful and relevant suggestions and brain food for the project from the Podcast Practical Ai by Chris Benson & Daniel Whitenack for how NLP problems are solved at scale in the industry
PS : For learning, I also completed Google 30 Days of Google cloud program to learn how to deploy and scale ML models on the cloud, for which i got goodies and Certificate , and Learning badege
Step 3 - Building the Model
I could write on a nice technical article on how I built my model (in short it was word2vec + Tf-Idf combined, if you want details to leave a comment below I’ll send my notes and whiteboard diagrams) but the real good takeaways and learning/challenges that I solved were
- How to efficiently save the models and load them back in memory and various file formats and their performance
- Performance difference between pandas and Numpy
- How much Cleaning and knowing your data is important and 80% of work in NLP
- No matter what another fancy state of the art solution you may find online, (as boring as it may sound and to explain to your colleagues or write on your resume )some custom solution based on classical known technique can give you a better and efficient solution if you know your data well.
- It’s every programmer’s dream to have a supercomputer equivalent processing power in their machine but try to use the cloud instead of burning your system down, especially for learning and side projects.
- Just like we have Github for code versioning there is Data version Control and other tools to be explored
- Make notes of what works to what not works and when reading some paper note down terms you don’t understand and look it up later
Lastly, write down the approach and your working as you build if you know you are going to write about it and don’t have to sum up in short like i did 🙈 and can write a good technical article about it.
PS: Added some articles I found online notes in reference at the end.
Step 3.5 - Teamwork Skills
In every project there is and should be a team lead or project in-charge and not pretend like no one is the team leader and everyone is in charge, being the one in this team and for other projects over years as a person in charge here are few things one should always take care off.
- Listen to every idea before you present your own
- Know the strong and weak areas of every team member and divide work accordingly.
- Meeting can be a real-time blackhole so set an agenda before the meeting or tell others in advance the topics to be discussed in teams and reschedule if nothing Important is to be discussed or even 1 member is missing.
- Make sure everyone gets a chance to what they want to work on and everyone does work and don’t keep members who just do MBA 101 stuff more than actual relevant work to an engineering project.
Step 4 - Present
Give a nice crisp presentation and don’t worry about the prize it’s learning that matters in long run.
Eat the Samosa (actual ones when you win)🥳
Reference
- https://towardsdatascience.com/how-we-built-an-ai-powered-search-engine-without-being-google-5ad93e5a8591
- https://juan0001.github.io/next-word-prediction/
- https://towardsdatascience.com/next-word-prediction-with-nlp-and-deep-learning-48b9fe0a17bf
- https://towardsdatascience.com/exploring-the-next-word-predictor-5e22aeb85d8f
- https://towardsdatascience.com/next-word-prediction-with-nlp-and-deep-learning-48b9fe0a17bf#:~:text=The%20model%20will%20consider%20the,pre-processing%20of%20the%20data
- https://github.com/starlordvk/Typing-Assistant