Exponential backoff with Jitter
A practical explanation of the thundering herd problem and why production retry logic needs jitter.
Exponential backoff with Jitter

Let’s discuss about the Thundering Herd problem.
You build a service. It’s solid. It handles millions of requests a day. Then, one day, the database connection pool hits a limit, or a load balancer decides to cycle pods. Your service flickers. It goes down for 500 milliseconds.
Your clients? They are well-behaved. They detect the failure, and they implement Exponential Backoff.
The Problem with Exponential Backoff
Exponential backoff is great. It says: “Hey, the server is struggling. Don’t hammer it. Wait 1 second. If that fails, wait 2 seconds. Then 4. Then 8.”
It’s logical. It’s clean. And in a vacuum, it’s perfect.
But we don’t live in a vacuum. We live in a distributed system with 10,000 clients.
If all 10,000 clients experience that 500ms failure at the exact same time, they all start their retry timers at the exact same time. They all wait 1 second. Then, at the 1-second mark, 10,000 requests hit your service again, simultaneously.
If the service wasn’t dead, it’s definitely dead now.
This is the synchronized retry storm. You aren’t just retrying; you’re coordinating an attack on your own infrastructure. You’ve replaced a service outage with a self-inflicted Distributed Denial of Service (DDoS) attack.
Enter Jitter
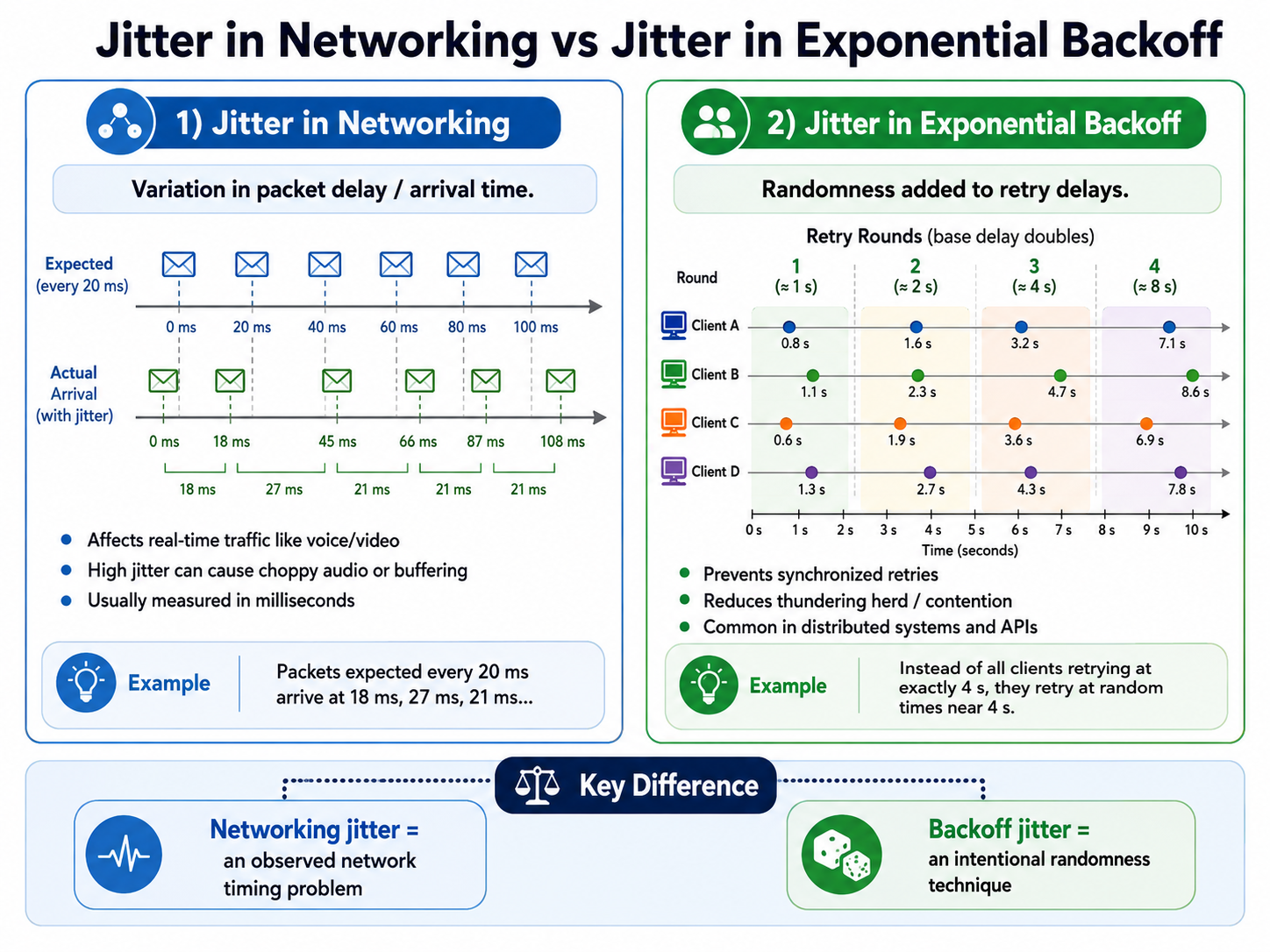
The solution isn’t to remove backoff—it’s to break the synchronization. We need Jitter.
Jitter is just a fancy word for randomness. Instead of every client waiting exactly $2^{attempt}$ seconds, we add a random variable to that duration.
If Client A waits 3.2 seconds, Client B waits 4.7 seconds, and Client C waits 2.9 seconds, the load on your service is smoothed out. Instead of a massive spike of 10,000 requests hitting the CPU, the requests arrive in a staggered, distributed stream.
Smooth traffic is manageable. Spiky traffic is lethal.
How to Implement It
There are three main ways to inject this randomness:
| Method | The Logic | The Goal |
|---|---|---|
| Full Jitter | random(0, backoff) | Maximum spread; ideal for avoiding collisions. |
| Equal Jitter | (backoff / 2) + random(0, backoff / 2) | Ensures a minimum wait time while still spreading the load. |
| Decorrelated | random(base, prev_delay * 3) | Organic, unpredictable delays that aren’t strictly tied to a single power-of-two curve. |

The “Must-Haves” for Production
If you’re going to implement retries, don’t just do backoff. You need these three safeguards:
- The Cap: Exponential backoff will eventually ask you to wait for hours if you aren’t careful. Set a
max_delay(e.g., 30 seconds).min(calculated_backoff, max_delay). - The Limit: Never retry forever. Set a
max_attempts. After 5 or 10 tries, give up and propagate the error. Maybe the service is dead, and you need a human to look at it, not a bot to keep spinning. - The Jitter: Always apply the randomness after calculating the backoff.
The Bottom Line
When you design your retry logic, stop thinking about a single client. Start thinking about the aggregate behavior of your system.
Ask yourself: “What happens if every single instance of this client decides to retry at the exact same moment?”
If the answer is a system crash, you don’t have a retry policy—you have a time bomb. Use jitter, break the synchronization, and give your services the breathing room they need to recover.