Why You Should Stop Creating Database Connections on Every Request
Connection pooling is one of those foundational backend architecture patterns that sounds basic, but still gets ignored in many real-world systems.
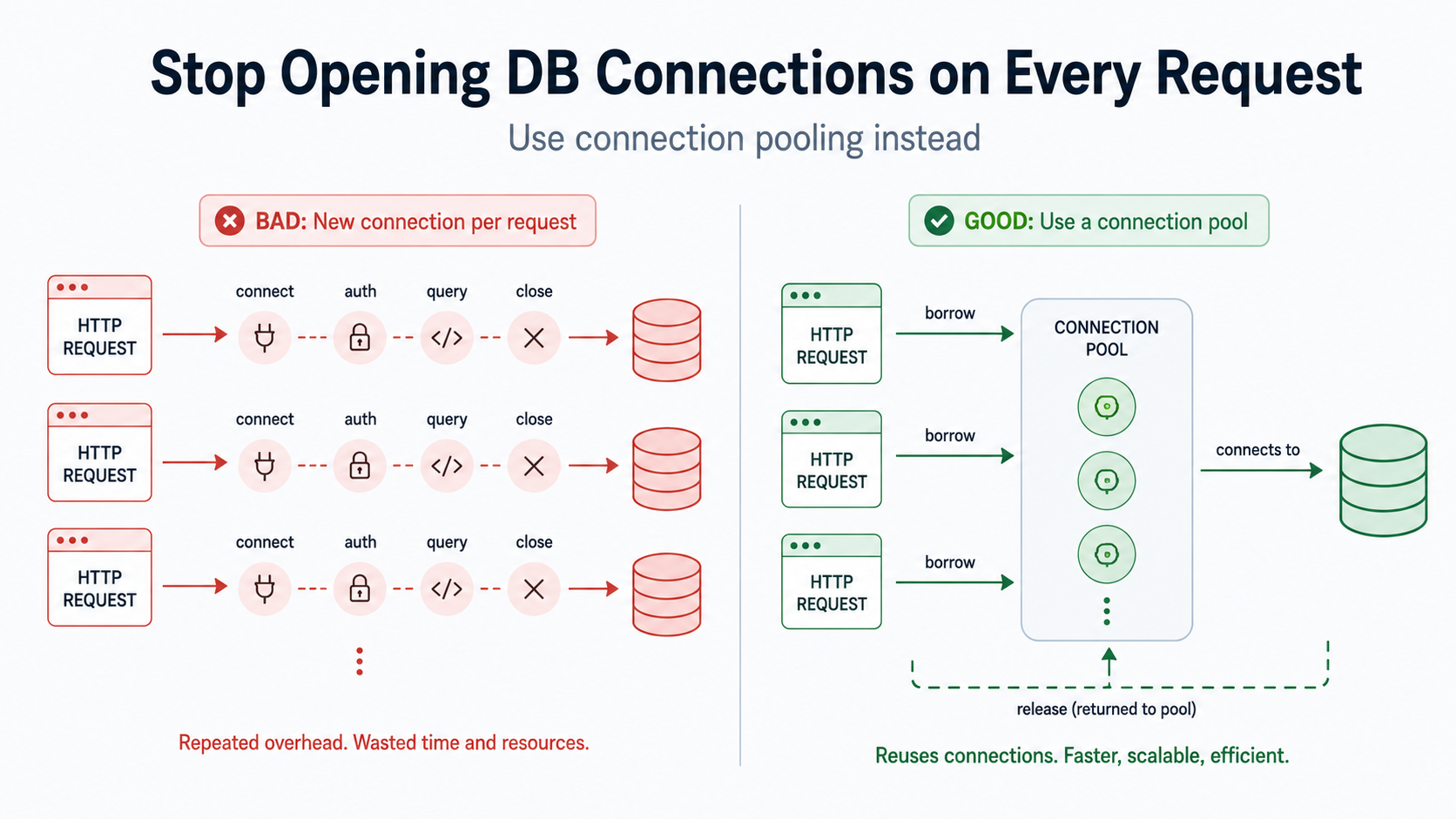
I still see applications that open a new database connection for every incoming HTTP request, run a query, and then immediately close the connection. It works. But it is incredibly expensive.
If your application does this, you are paying the connection setup cost over and over again. At low traffic, you may not notice. At production scale, this becomes wasted CPU, wasted memory, higher latency, and unnecessary pressure on your database.
Let’s break down why this happens, the underlying mechanics, and why connection pooling is usually the right fix.
The Problem: Creating Connections as if They Are Free
A naive backend implementation often treats every request as completely independent. The request comes in, the application opens a database connection, it executes a query, and it closes the connection.
1
2
3
4
5
6
HTTP request
-> open database connection
-> authenticate
-> run query
-> close database connection
-> return response
This looks clean from the application’s point of view, but underneath the hood, a massive amount of heavy lifting is happening. Opening a database connection usually involves:
- TCP handshake:The initial three-way handshake to establish a network socket.
- TLS/SSL negotiation: (If encrypted) Multiple round trips to exchange certificates and agree on cryptographic keys.
- Database authentication:The database engine validating your credentials, checking permissions, and spinning up a worker process or thread.
- Protocol negotiation:The client and server agreeing on encoding, character sets, and protocol versions.
- Query execution: The actual useful work.
- Connection teardown:Gracefully closing the network sockets and freeing database-side worker memory.
The actual query may be trivial. Maybe it is just:
SQL
1
SELECT * FROM books WHERE id = 42;
But before the database can even look at that query, the application and database need to establish that connection. That setup has a significant cost.
If the database is running on another machine, another availability zone, or a managed cloud service, the cost becomes even more noticeable because network latency is now involved. Instead of spending most of your time doing useful database work, your system spends too much time repeatedly setting up and tearing down connections. That is the bottleneck.
The “Stateless Connection” Antipattern
Stateless application servers are excellent. Stateless database connections per request are a disaster. There is a critical difference.
A stateless backend means any application instance can handle any incoming request. That is useful for horizontal scaling. But it does not mean every request should create a brand-new database connection.
1
2
3
4
request 1 -> connect -> query -> disconnect
request 2 -> connect -> query -> disconnect
request 3 -> connect -> query -> disconnect
request 4 -> connect -> query -> disconnect
This is simple, but wasteful. You are not just executing queries; you are repeatedly paying a connection “tax” on every single request.
The Solution: Connection Pooling
Connection pooling fixes this by keeping a managed set of database connections open and reusing them. Instead of creating a new connection every time a request arrives, the application borrows an existing, “warm” connection from the pool.
The request runs its query, and then the connection is returned to the pool. The underlying TCP socket stays open.
1
2
3
4
5
HTTP request
-> borrow existing connection
-> run query
-> return connection to pool
-> return response
Instead of a constant cycle of connection churn, the lifecycle transforms:
1
2
3
borrow -> query -> return
borrow -> query -> return
borrow -> query -> return
The difference is simple, but the impact can be massive. You avoid repeated handshakes, reduce connection churn, lower the load on the database engine, improve latency, and make the system predictable under sudden spikes in traffic.
A Language-Agnostic Mental Model
Almost every backend stack has some version of this abstraction.
- In a Java Spring Bootapplication, the connection pool (like HikariCP) usually sits behind the configured
DataSource. - In a Pythonapplication, it may be a pool object from the database driver or an ORM like SQLAlchemy.
- In a Node.jsapplication, it may be a pool from client libraries like
pgormysql2. - In Go, connection pooling is implicitly managed out-of-the-box by the standard
database/sqlpackage.
The syntax changes, but the architecture does not. You initialize the pool once when the application boots up. Then, every request borrows from that pool.
Python
#
1
2
3
4
5
6
7
8
9
10
11
12
13
# Conceptually:
pool = create_connection_pool(
min_connections = 2,
max_connections = 10
)
function handle_request(request):
connection = pool.borrow()
try:
result = connection.query("SELECT ...")
return result
finally:
pool.release(connection) # Put it back, don't close it!
The pool lives longer than a single request. The connection is reused. The request does not own the connection forever.
Why Pooling Is Faster (And Protects the DB)
A database connection is not just a passive variable in your code. It represents real resources allocated on both sides of the network.
On the application side, there are sockets, file descriptors, and client-side memory buffers. On the database side, there is memory allocation, process or thread state, authentication context, and connection management overhead.
Pooling keeps those resources warm. The first request may pay the connection setup cost, but the next thousand requests reap the benefits of reuse. In many systems, this cuts query latency dramatically, especially for small, frequent queries where the network handshake originally took up 90% of the total request time.
The Power of Backpressure
Connection pooling is not only about raw speed; it is about architectural control. A pool has a maximum size. For example:
maximum pool size = 10
This means the application instance can use at most 10 database connections concurrently. If 50 requests arrive simultaneously and all of them need to hit the database, only 10 can actively execute queries. The other 40 requests wait in a queue for a connection to be returned.
At first glance, this sounds like a bottleneck. In reality, it is backpressure protection. Without a pool limit, your application might spawn 50 concurrent database connections, then 500, then 5000 under a surge. The database will choke on context switching, run out of RAM, and crash.
A database under controlled, queued pressure is a predictable system. A database drowning in raw, unthrottled connections is a failing system.
More Connections Does Not Mean More Throughput
A common mistake is increasing the pool size whenever the application feels slow. If 10 connections are good, maybe 100 are better, right? Not necessarily.
Every database engine has a sweet spot for how many active connections it can handle efficiently relative to its CPU cores and I/O capacity. Too many connections can increase memory usage, scheduling overhead, lock contention, and disk thrashing. At some point, adding more connections makes the database busier doing connection managementinstead of query execution.
When calculating your connection limits, always remember this equation:
1
Total Database Connections = Number of App Instances × Pool Size Per Instance
If you horizontally scale to 8 application instances, and each has a pool size of 20, your database must support up to 160 concurrent connections. That aggregate number matters far more than the pool size of one isolated instance.
When a Simple Pool Query Is Enough
For independent, stateless operations, borrowing a connection briefly and implicitly is perfect.
Python
#
1
2
3
function get_book(book_id):
# The pool handles borrowing and returning automatically
return pool.query("SELECT * FROM books WHERE id = ?", [book_id])
The application can borrow any available connection, run the SELECT, UPDATE, or INSERT, and return it immediately. It doesn’t care whichspecific connection it used, because the operation is entirely self-contained.
When You Need a Dedicated Connection (Transactions)
There are cases where a single query is not enough. Sometimes multiple queries must succeed or fail together as a unit of work. That is an ACID transaction.
SQL
#
1
2
3
4
5
BEGIN TRANSACTION;
INSERT INTO orders (...);
INSERT INTO order_items (...);
UPDATE inventory SET stock = stock - 1 WHERE id = ?;
COMMIT;
These operations must run on the exact same database connection. Why? Because transaction state belongs explicitly to the connection session on the database server. You cannot execute BEGINon connection A, run an INSERTon connection B, and call COMMITon connection C. The database will treat them as unrelated actions.
For transactions, you must explicitly borrow one specific connection, pin your queries to it for the duration of the block, and release it when done.
Python
#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
connection = pool.borrow()
try:
connection.execute("BEGIN")
connection.execute("INSERT INTO orders ...")
connection.execute("INSERT INTO order_items ...")
connection.execute("UPDATE inventory ...")
connection.execute("COMMIT")
except error:
connection.execute("ROLLBACK")
raise error
finally:
pool.release(connection) # CRITICAL!
The finallyblock is non-negotiable. If you fail to return the connection to the pool due to an unhandled exception, you leak it. If enough connections leak, the pool dries up, and subsequent requests will hang indefinitely or time out. Connection leaks are a catastrophic production bug because everything looks fine at startup, but the system degrades slowly until it completely freezes.
Keep Transactions Short
While using a dedicated connection for a transaction is correct, holding it for too long is a major antipattern. A transaction should execute the minimum amount of database work required and immediately yield the connection back to the pool.
Never hold a database connection open while performing slow, unrelated I/O operations outside the database.
Bad Pattern
1
2
3
4
5
6
begin transaction
-> update database
-> call external payment gateway API (HTTP request - 2 seconds)
-> send email via SMTP (1 second)
commit transaction
release connection
Result: This connection was locked up for over 3 seconds doing nothing but waiting on external networks.
Better Pattern
1
2
3
4
5
6
7
8
begin transaction
-> update database
commit transaction
release connection
# Database connection is safe in the pool for others to use
-> call external payment gateway API
-> send email via SMTP
Your pool is a highly shared resource. Every extra second a request holds an idle connection is a second another incoming request is forced to block and wait.
Connection Pooling Does Not Fix Everything
Connection pooling is essential backend hygiene, but it is not magic. It will not fix:
- Missing database indexes causing full table scans
- Inbound $N+1$query patterns in your ORM
- Unbounded result sets (
SELECT *on a table with 10 million rows) - Long-running transactions holding application locks
- Under-provisioned database hardware (CPU/RAM exhaustion)
If your underlying query is fundamentally slow, pooling won’t make it fast. If your application runs too many queries per request, pooling won’t remove them. Connection pooling solves exactly one problem: resource reuse. That is deeply valuable, but it is just one layer of building high-performance backend systems.
Summary Checklist
- Stop opening and closing connections manually on every single HTTP request.
- Initialize a shared poolat application startup and reuse those warm connections.
- Always use a
finallyblock to release connections when manually managing transactions. - Keep your transaction boundaries tight—never wrap external API calls inside database transactions.
- Calculate total concurrencyby multiplying your pool size by your total scaled application instances.