[Notes]Data Mining and Data Warehousing
Unit -6
Data Mining Techniques
Several core techniques that are used in data mining describe the type of mining and data recovery operation
1. Association Rule
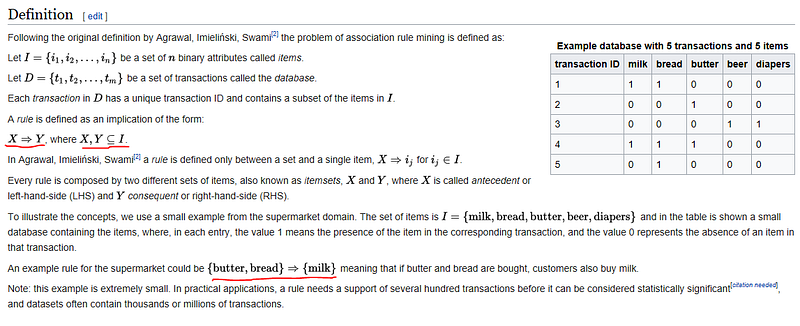
Association rule learningis arule-based machine learningmethod for discovering interesting relations between variables in large databases
Association rules are if/then statements that help uncover relationships between seemingly unrelated data in arelational databaseor other information repository. An example of an association rule would be “If a customer buys a dozen eggs, he is 80% likely to also purchase milk.”
Such information can be used as the basis for decisions about marketing activities such as, e.g., promotionalpricingorproduct placements.
Association rules are created by analyzing data for frequent if/then patterns and using the criteriasupportandconfidenceto identify the most important relationships.
Supportis an indication of how frequently the items appear in the database.Confidenceindicates the number of times the if/then statements have been found to be true.
Apriori algorithm
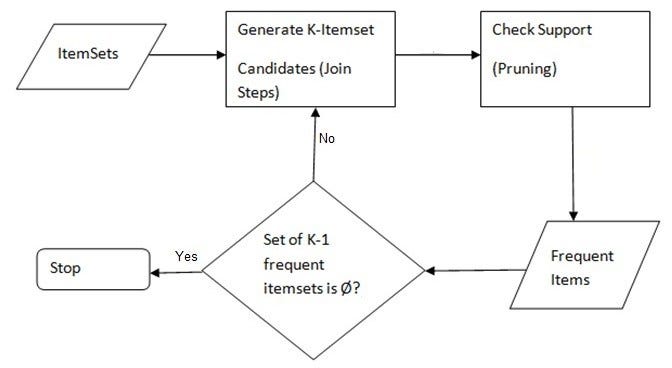
Aprioriis an influential algorithm for frequent item set mining andassociation rule learningover transactionaldatabases. It proceeds by identifying the frequent individual items in the database and extending them to larger and larger item sets as long as those item sets appear sufficiently often in the database.
- It uses abottom up approachwhere frequent subsets are extended one item a time
- It is designed to operate in database containing transactions
- Frequent Itemsets: all the sets which contain items with min_support
Apriori Property
Any subset if frequent items set must be frequent (ie if a subset cannot pass the frequent test its superset will also fail )
‘L’ are those items which support minimum support
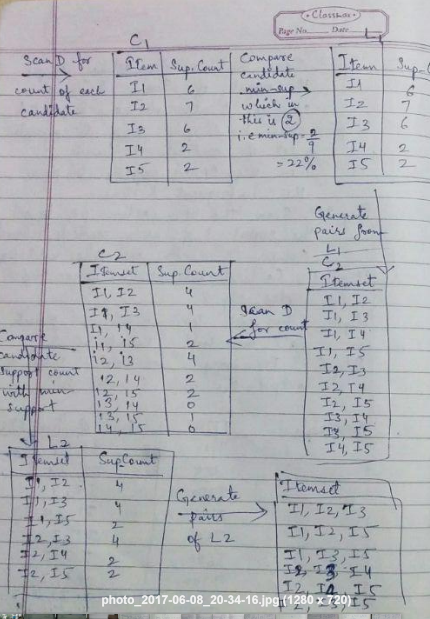
Step 1: Scan the transaction database to get the support of search 1-itemset , compare S with with min_suport and get table 1
Step 2 : use L(k-1), join L(k-1 ) to generate a set of candidate k itemset and then use the apriori algo to prune out the unfortunate items
Step 3: Scan the transcations DB to get support of each candidate K itemset , Compare S with _ support & get (k)
Step 4 : Candidate set = Null , if yess step 5 else step 2
Step 5: for each frequent itemset 1 generate all non empty subset of 1
Step 6 : for every non empty subset of 1 output the rule s=(1–2)
Pros of the Apriori algorithm
- It is an easy-to-implement and easy-to-understand algorithm.
- It can be used on large itemsets.
Cons of the Apriori Algorithm
- Sometimes, it may need to find a large number of candidate rules which can be computationally expensive.
- Calculating support is also expensive because it has to go through the entire database.
Clustering Technique
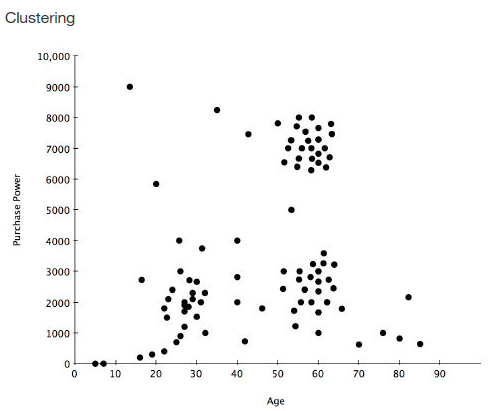
Cluster analysisorclusteringis the task of grouping a set of objects in such a way that objects in the same group (called acluster) are more similar (in some sense or another) to each other than to those in other groups (clusters).
- Cluster if data objects can be considered as one group
- advantage of cluster over classification is that it is adaptable to change and single out useful feature and distinguish from the group
- Unsupervised learning
Applications : market research and pattern learning , used in field of biology , fraud detection
Requirements of Clustering
- Scalbility
- ability to deal with different kind of attributes
- high dimensionality
- ability to deal noisy data
5. InterpretabilityThe clustering results should be interpretable, comprehensible, and usable.
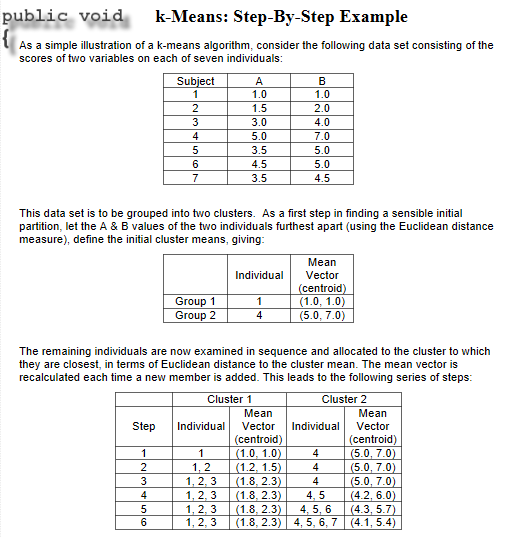
K means Clustering
It aims to partition N observations into K clusters in which each observation belongs to cluster with nearest mean serving as a prototype of the cluster it works with the large database
Descision Tree
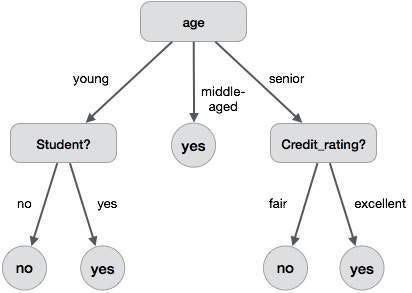
A decision tree is a structure that includes a root node, branches, and leaf nodes. Each internal node denotes a test on an attribute, each branch denotes the outcome of a test, and each leaf node holds a class label. The topmost node in the tree is the root node.
The following decision tree is for the concept buy_computer that indicates whether a customer at a company is likely to buy a computer or not. Each internal node represents a test on an attribute. Each leaf node represents a class.
The benefits of having a decision tree are as follows −
- It does not require any domain knowledge.
- It is easy to comprehend.
- The learning and classification steps of a decision tree are simple and fast.
Tree Pruning
Tree pruning is performed in order to remove anomalies in the training data due to noise or outliers. The pruned trees are smaller and less complex.
Tree Pruning Approaches
Here is the Tree Pruning Approaches listed below −
- Pre-pruning− The tree is pruned by halting its construction early.
- Post-pruning — This approach removes a sub-tree from a fully grown tree.
Neural Network
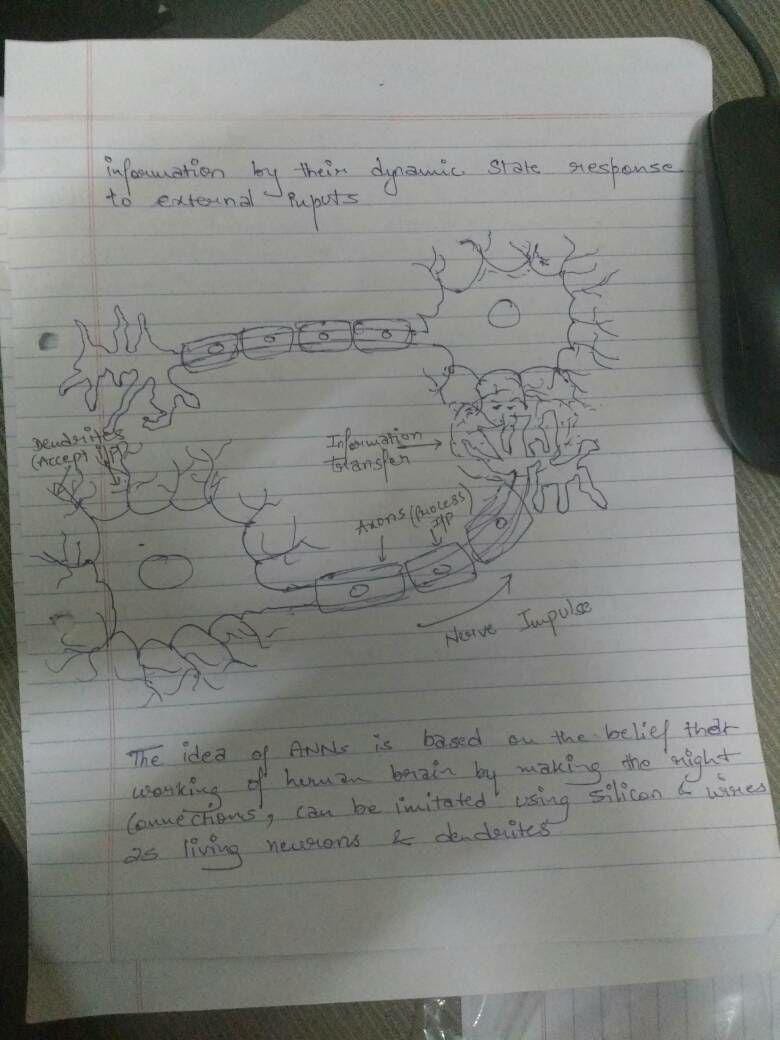
In information technology, a neural network is a system of hardware and/or software patterned after the operation of neurons in the human brain. Neural networks — also called artificial neural networks — are a variety ofdeep learningtechnologies. Commercial applications of these technologies generally focus on solving complex
A neural network usually involves a large number ofprocessorsoperating in parallel and arranged in tiers. The first tier receives the raw input information — analogous to optic nerves in human visual processing. Each successive tier receives the output from the tier preceding it, rather than from the raw input — in the same way neurons further from the optic nerve receive signals from those closer to it. The last tier produces the output of the system
Each processingnodehas its own small sphere of knowledge, including what it has seen and any rules it was originally programmed with or developed for itself. The tiers are highly interconnected, which means each node intiernwill be connected to many nodes in tiern-1 — its inputs — and in tiern+1,which provides input for those nodes. There may be one or multiple nodes in the output layer, from which the answer it produces can be read.
Typically, a neural network is initially trained, or fed large amounts of data. Training consists of providing input and telling the network what the output should be. For example, to build a network to identify the faces of actors, initial training might be a series of pictures of actors, non-actors, masks, statuary, animal faces and so on. Each input is accompanied by the matching identification, such as actors’ names, “not actor” or “not human” information. Providing the answers allows the model to adjust its internal weightings to learn how to do its job better.
Fuzzy Logic
Fuzzy logic is an approach to computing based on “degrees of truth” rather than the usual “true or false” (1 or 0)Booleanlogic on which the modern computer is based.
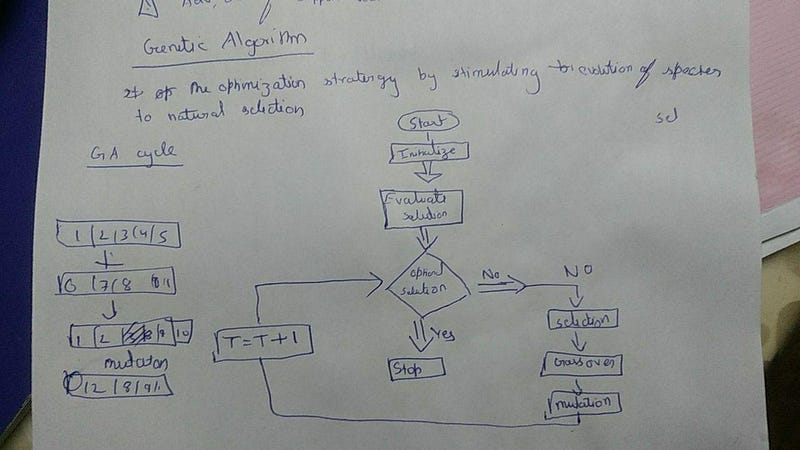
Genetic Algorithm
## **Unit-7** ## **Text database Mining** Text databases consist of huge collection of documents. They collect these information from several sources such as news articles, books, digital libraries, e-mail messages, web pages, etc. Due to increase in the amount of information, the text databases are growing rapidly. In many of the text databases, the data is semi-structured. For example, a document may contain a few structured fields, such as title, author, publishing_date, etc. But along with the structure data, the document also contains unstructured text components, such as abstract and contents. Without knowing what could be in the documents, it is difficult to formulate effective queries for analyzing and extracting useful information from the data. Users require tools to compare the documents and rank their importance and relevance. Therefore, text mining has become popular and an essential theme in data mining. ## Information Retrieval Information retrieval deals with the retrieval of information from a large number of text-based documents. Some of the database systems are not usually present in information retrieval systems because both handle different kinds of data. Examples of information retrieval system include − - Online Library catalogue system - Online Document Management Systems - Web Search Systems etc. **Note**− The main problem in an information retrieval system is to locate relevant documents in a document collection based on a user’s query. This kind of user’s query consists of some keywords describing an information need. In such search problems, the user takes an initiative to pull relevant information out from a collection. This is appropriate when the user has ad-hoc information need, i.e., a short-term need. But if the user has a long-term information need, then the retrieval system can also take an initiative to push any newly arrived information item to the user. This kind of access to information is called Information Filtering. And the corresponding systems are known as Filtering Systems or Recommender Systems. ## Basic Measures for Text Retrieval We need to check the accuracy of a system when it retrieves a number of documents on the basis of user’s input. Let the set of documents relevant to a query be denoted as {Relevant} and the set of retrieved document as {Retrieved}. The set of documents that are relevant and retrieved can be denoted as {Relevant} U(inverted){Retrieved}. This can be shown in the form of a Venn diagram as follows −  There are three fundamental measures for assessing the quality of text retrieval − - Precision - Recall - F-score ## Precision Precision is the percentage of retrieved documents that are in fact relevant to the query. Precision can be defined as − ``` Precision= |{Relevant} intersection{Retrieved}| / |{Retrieved}| ``` ## Recall Recall is the percentage of documents that are relevant to the query and were in fact retrieved. Recall is defined as − ``` Recall = |{Relevant} Intersection{Retrieved}| / |{Relevant}| ``` ## F-score F-score is the commonly used trade-off. The information retrieval system often needs to trade-off for precision or vice versa. F-score is defined as harmonic mean of recall or precision as follows − ``` F-score = recall x precision / (recall + precision) / 2 ``` ## **World Wide Web Mining** The World Wide Web contains huge amounts of information that provides a rich source for data mining. ## Challenges in Web Mining The web poses great challenges for resource and knowledge discovery based on the following observations − - **The web is too huge**− The size of the web is very huge and rapidly increasing. This seems that the web is too huge for data warehousing and data mining. - **Complexity of Web pages**− The web pages do not have unifying structure. They are very complex as compared to traditional text document. There are huge amount of documents in digital library of web. These libraries are not arranged according to any particular sorted order. - **Web is dynamic information source**− The information on the web is rapidly updated. The data such as news, stock markets, weather, sports, shopping, etc., are regularly updated. - **Diversity of user communities**− The user community on the web is rapidly expanding. These users have different backgrounds, interests, and usage purposes. There are more than 100 million workstations that are connected to the Internet and still rapidly increasing. - **Relevancy of Information**− It is considered that a particular person is generally interested in only small portion of the web, while the rest of the portion of the web contains the information that is not relevant to the user and may swamp desired results. ## Mining Web page layout structure The basic structure of the web page is based on the Document Object Model (DOM). The DOM structure refers to a tree like structure where the HTML tag in the page corresponds to a node in the DOM tree. We can segment the web page by using predefined tags in HTML. The HTML syntax is flexible therefore, the web pages does not follow the W3C specifications. Not following the specifications of W3C may cause error in DOM tree structure. The DOM structure was initially introduced for presentation in the browser and not for description of semantic structure of the web page. The DOM structure cannot correctly identify the semantic relationship between the different parts of a web page. ## Vision-based page segmentation (VIPS) - The purpose of VIPS is to extract the semantic structure of a web page based on its visual presentation. - Such a semantic structure corresponds to a tree structure. In this tree each node corresponds to a block. - A value is assigned to each node. This value is called the Degree of Coherence. This value is assigned to indicate the coherent content in the block based on visual perception. - The VIPS algorithm first extracts all the suitable blocks from the HTML DOM tree. After that it finds the separators between these blocks. - The separators refer to the horizontal or vertical lines in a web page that visually cross with no blocks. - The semantics of the web page is constructed on the basis of these blocks. The following figure shows the procedure of VIPS algorithm −  ## Alternative Syllabus ________________________________________________________________________ ## **Strategy in Efficient Data mining** **Step 1: Handling of incomplete data** Incomplete data affects classification accuracy and hinders[effective data mining](https://searchbusinessanalytics.techtarget.com/feature/An-introduction-to-data-mining). The following techniques are effective for working with incomplete data. 1. **multi-task learning (MTL)**: the learning of a problem in relation to others) for pattern classification, with missing inputs, can be compared with representative procedures used for handling incomplete data on two well-known data sets. 2. Another[data mining technique](https://searchbusinessanalytics.techtarget.com/tip/Most-businesses-think-small-when-it-comes-to-data-mining-techniques)is based on the evolution of strategies built using**parametric and non-parametric imputation methods** 3. The ISOM-DH model handles incomplete data using independent component analysis (ICA) and self-organizing maps (SOM). It uses existing data to estimate the missing data and visualize the handled high-dimensional data. **Step 2: Ensure efficiency and scalability of data mining algorithms\** A great deal of expertise and effort is currently required for the implementation, maintenance, and performance-tuning of a parallel data mining application 1. Ensure parallel and scalable execution of data mining algorithms. 2. Opt for scalable data mining instead of mere[associations](https://searchbusinessanalytics.techtarget.com/definition/association-rules-in-data-mining)when mining market basket data. 3. Remove barriers to the widespread adoption of support vector machines. **Step 3: Mining of large databases** 1. SQL implementations for processing in the DBMS. 2. Tight-coupling, primarily with user-defined functions. 3. Encapsulation of the data mining algorithm in a stored procedure. 4. Caching the data to a file system on the fly, then mining. **Step 4: Handling of relational and complex data types** Its critical to develop a system to support the mining of multiple-level knowledge in large relational databases and data warehouses. This requires tight integration of**online analytical processing (**[**OLAP**](https://searchbusinessintelligence.techtarget.in/news/2240024045/OLAP-and-data-mining-Whats-the-difference)**)**with a wide spectrum of data mining functions including characterization, association, classification, prediction, and clustering. 1. OLAP-based induction 2. Multidimensional statistical analysis 3. Analyzing graph databases by aggregate queries **Step 5: Data mining techniques for heterogeneous databases** Heterogeneous database systems play a vital role in the information industry in 2011. Data warehouses must support data extraction from multiple databases to keep up with the trend. Example : three[heterogeneous data mining](https://searchoracle.techtarget.com/tip/Successful-data-mining-requires-work)programs are needed to model the behavior of telecom organizations 1. Client Attribute model 2. Client Characteristics and Usage model 3. A third model based on the clustering of the above 2 ## Data Mining Model 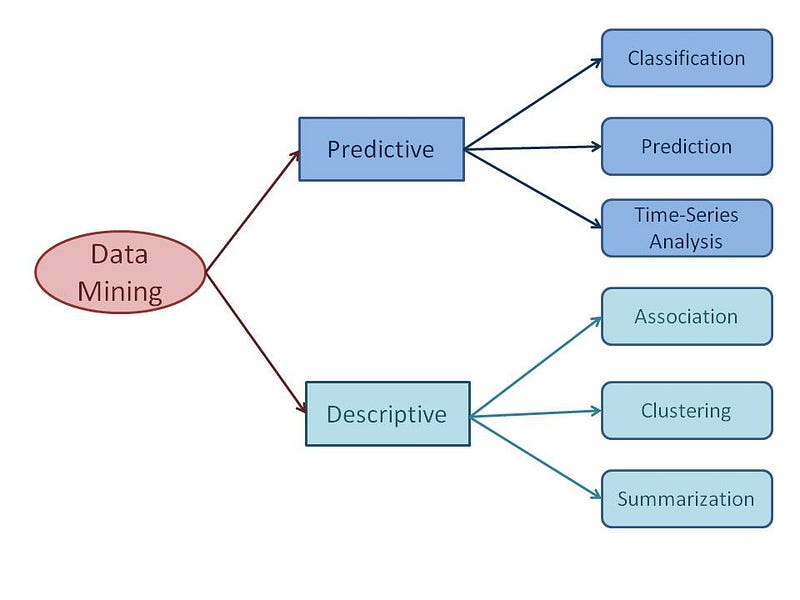 **Time series*analysis***comprises methods for analyzing time series data in order to extract meaningful statistics and other characteristics of the data. **Summarization**is a key data mining concept which involves techniques for finding a compact description of a dataset ## Data Mining Applications Here is the list of areas where data mining is widely used − - Financial Data Analysis - Retail Industry - Telecommunication Industry - Biological Data Analysis - Other Scientific Applications - Intrusion Detection ## Biological Data Analysis In recent times, we have seen a tremendous growth in the field of biology such as genomics, proteomics, functional Genomics and biomedical research. Biological data mining is a very important part of Bioinformatics. Following are the aspects in which data mining contributes for biological data analysis ## **Intrusion Detection** Intrusion refers to any kind of action that threatens integrity, confidentiality, or the availability of network resources. In this world of connectivity, security has become the major issue. With increased usage of internet and availability of the tools and tricks for intruding and attacking network prompted intrusion detection to become a critical component of network administration. Here is the list of areas in which data mining technology may be applied for intrusion detection ## Reference - [Original Medium article](https://medium.com/@harshityadav95/data-mining-and-data-warehousing-8068df0798)